The Creative AI Stack
08 Jan 25
How things change. Not so long ago, we were amazed at the strange smeary stills created by early generative tools. Now it turns out you can make entire walking-talking, cinematic adverts with just a handful of prompts. Not only that, you can do it in a way that can be personalised into multiple different films - to specifically target people or cohorts. We know this, because that's exactly what we did for KPMG. Here's how we made 50 (yes 50!) AI adverts for them. (Scroll to the end to see the full video)
In the latter part of 2024, Tilt were scheduled to shoot a walk-and-talk style film for KPMG – shot in a contemporary warehouse space, with a lead actor, a bunch of props, and a whole load of complex post-production CGI. We’d recently been given BETA access to the new AI tool LipDub. The slick marketing video starring Will Smith promises ‘The highest quality AI lip sync at Hollywood standards’. Our plan was to use LipDub to personalise our walk-and-talk film, lip syncing bespoke scripts for targeted key KPMG clients.
The ambitious target of 50 different films, would each offer bespoke info based on the findings from KPMG’s yearly Customer Experience Excellence report for each specific individual or team. The point of it all was to drive client sign-up for The AI-X Hour – a face-to-face meeting to further discuss the report findings and showcase AI-X, KPMG’s AI powered customer excellence initiative.
In the lead-up to the shoot, we tested LipDub under different lighting conditions in the Tilt studio, put together moodboards, scripts, sketched the storyboard, searched for actors and locations etc. The topic of the film revolves around AI and customer excellence, and this got me thinking. A couple of weeks prior to the film shoot, I nervously asked the Tilt team:
“Shouldn’t we be making it all with AI?”
Mic drop moment.
The reasoning was to show KPMG’s clients by example, how brilliant they are with Artificial Intelligence in customer experience. Same scripts, same storyboards, same 50 versions. Just no physical film shoot. No one was quite sure if it could be done, but being Tilters, this is our happy place. With a thumbs up from the client, the challenge was on!

Designing a creative AI stack
Of course, this was not about simply ‘pushing the AI button’. It may become the case in the future, but in the latter part of 2024 to produce 50 films to high production values, our task revolved around designing a dependable creative AI stack (similar to an AI stack in dev). Think of this as a collection of AI tools and technologies designed to collaboratively generate, enhance, and streamline creative processes such as writing, visual art, animation, and audio production. In this case, our chosen AI tools were:
• ChatGPT – to aid script development
• MidJourney – to provide high quality stills
• Runway Gen-3 – to animate the stills
• Lumalabs Dream Machine – an alternative to animate the stills
• Topaz Gigapixel AI – to upscale everything
• Eleven labs – to design and export vocal tracks
• HeyGen – to produce training lip sync shots for LipDub
• LipDub – to create dynamic lip syncs
Scripts
We wrote a basic script for sign-off, with multiple modular elements that could be changed – name of individual, name of company, stats, ranking, sector trends, different advice etc. and developed this out into 50 different scripts based on a spreadsheet of CEE information related to each of the KPMG clients. Utilising AI to the max, ChatGPT was helpful here. Anyone who’s ever written a half decent script will know that ChatGPT can only get you so far. It was useful however in bouncing ideas and condensing huge amounts of information into short paragraphs, to help with the writing process.
MidJourney
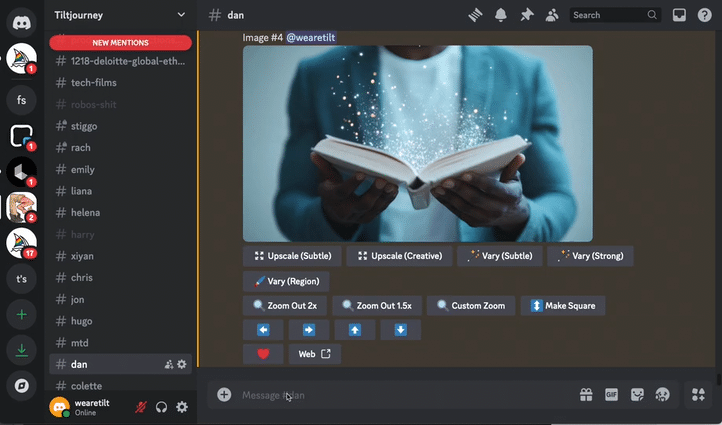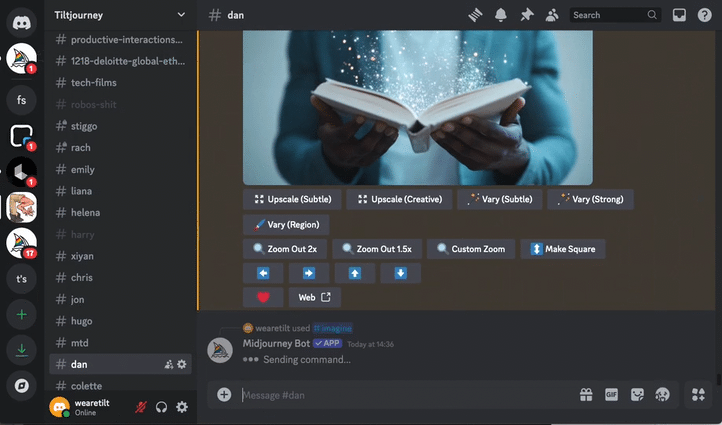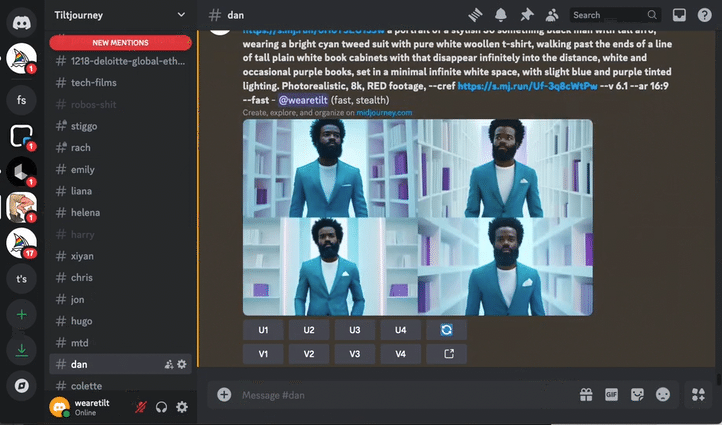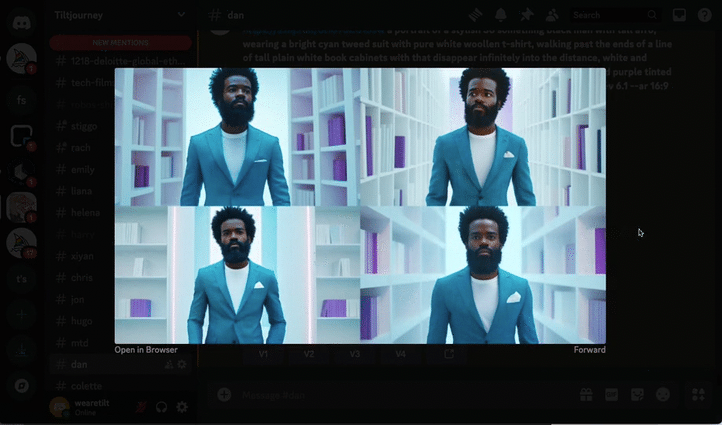
Storyboards
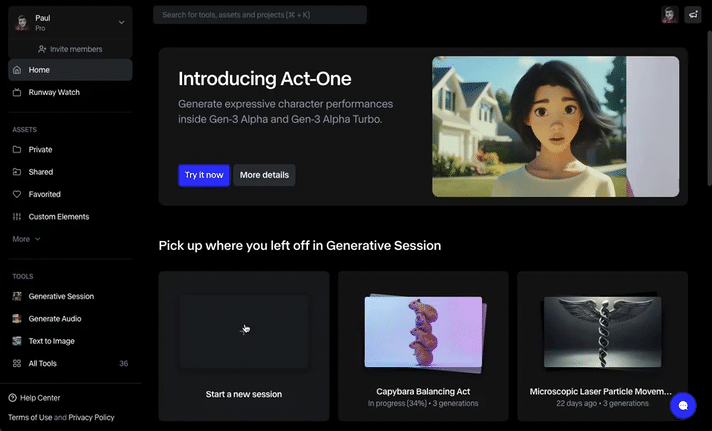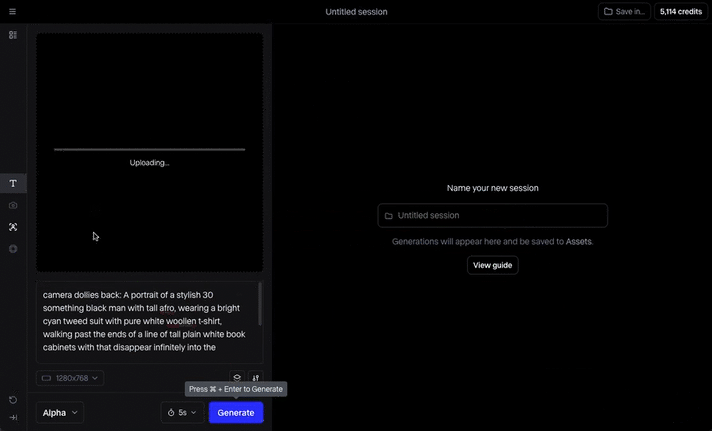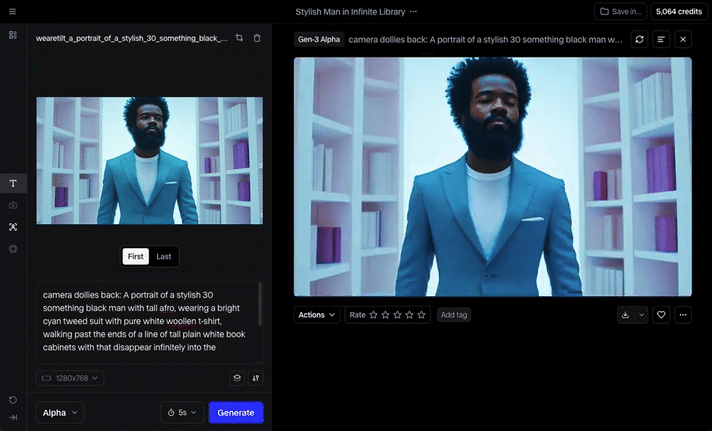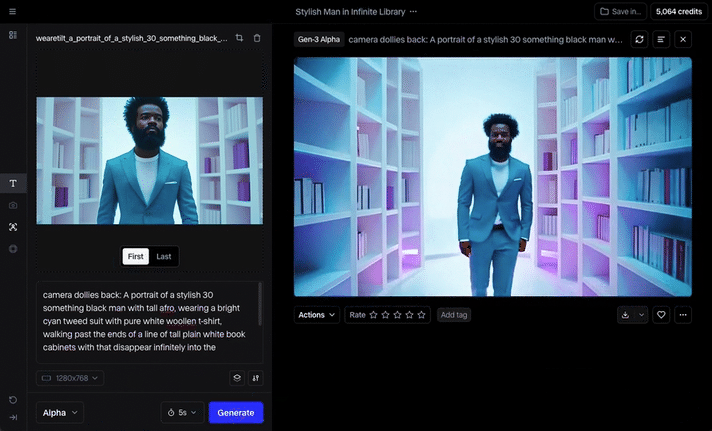
MidJourney was our tool of choice to render the original film’s sketched storyboard. MidJourney is reputable, and consistently produces cinematic quality imagery and it is our usual go-to. Being that we were now relying purely on an AI actor instead of a charismatic real person, we added extra scenes to the film to fully lean into the possibilities that AI can offer, rather than this being a detriment. The first step was to create a high res, full height, completely generative narrator avatar, and use him as our MidJourney character reference (—cref) for consistency. For best practice, we were careful not to reference any actual individual in our prompts. Aeon as he’s being referred to, is a completely new ‘person’. From Aeon’s avatar, we were then able to create the entire storyboard of our walking talking narrator – essentially our base images for each scene of the film to be animated.
Animation
To animate our MidJourney stills, we used two different tools. Runway’s Gen-3 is incredibly capable at producing high quality moving sequences – sometimes indistinguishable from real footage. It also offers basic lip sync (without training data), which unfortunately was not convincing enough for this project. The main downside of Gen-3 in my experience is there can sometimes be what I can only describe as an ‘over-sharpened‘ look. Also, it can often feel like feeding endless coins into a fruit machine and receiving only sporadic ‘wins’. When it’s good, it’s great, but very often it will go off on a peculiar tangent as the sequence progresses. You just have to accept that you’ll need to waste a lot of credits to get something brilliant. Mid-project, camera controls were added to Gen-3 as an update which were incredibly useful, but the process was still time-consuming and costly to achieve great results.
Gen-3
Dream Machine
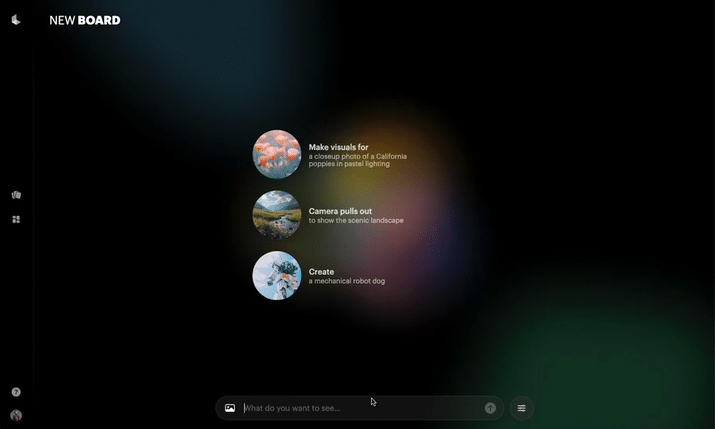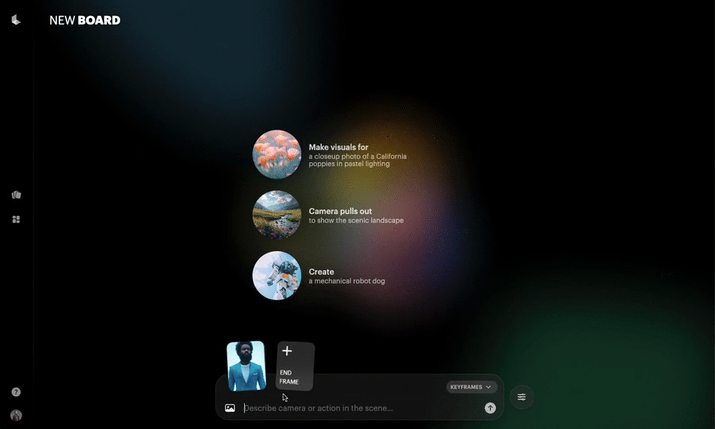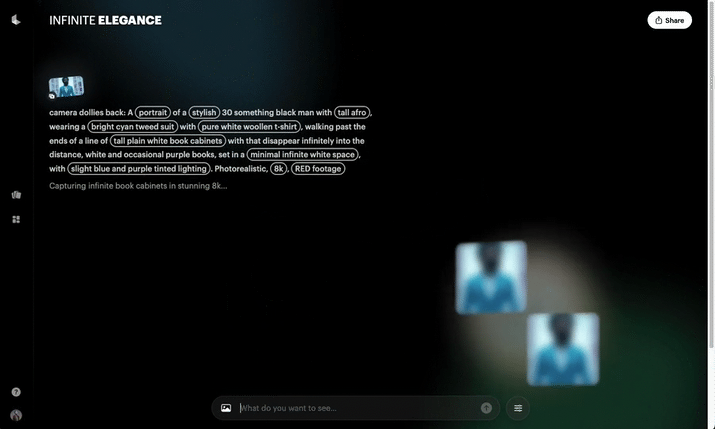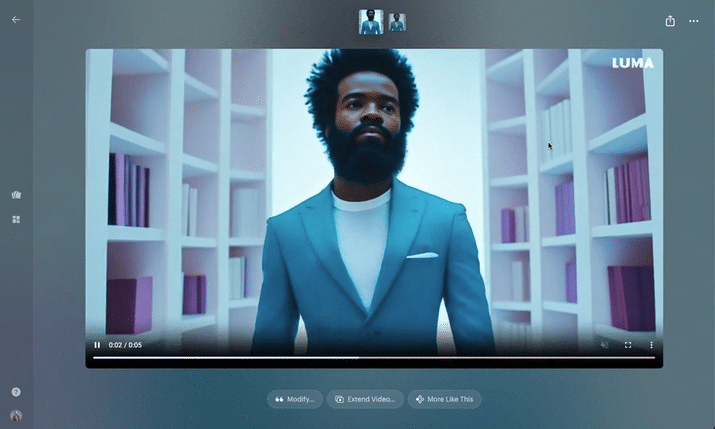
LumaLabs’ Dream Machine on the other hand offers something slightly different. It doesn’t seem to go as far with the small details, and has a softer look than Gen-3, but at the time of writing, it holds the key advantage of allowing you to add a start and end input still frame. This equals predictability of output, and saves a lot of wasted effort/credits. In this respect, I feel Dream Machine probably takes the biscuit. Not only are the animations more consistently correct, but you can also achieve mind-blowing transitions from one scene to the next by adding two completely different stills for the beginning and end. What Dream Machine does in-between feels like a completely new artform for scene transitions. Ultimately, whether using Gen-3 or Dream Machine, we brought each scene to life through prompt trial and error, to create a collection of dynamic 10 second clips that would serve as footage for the edit: narrator walking, blinking, sitting, gesturing, cutaway shots, cgi type sequences etc. – but with no talking as yet.
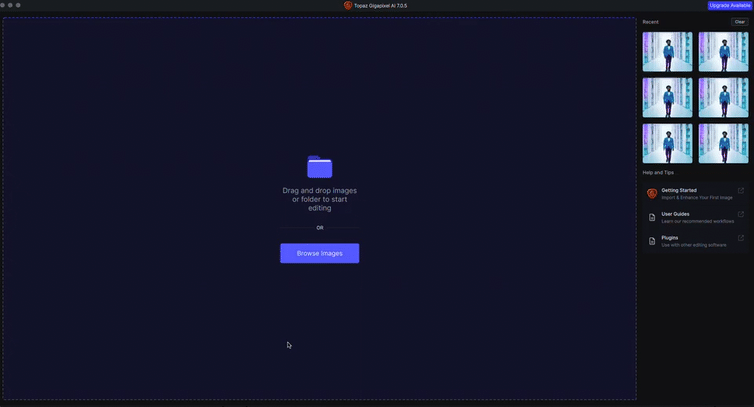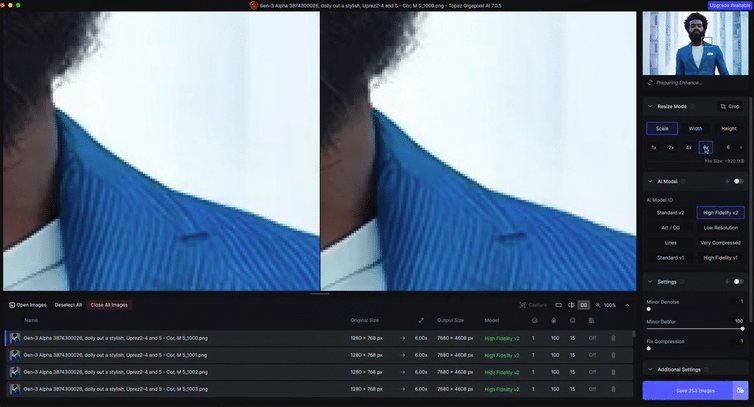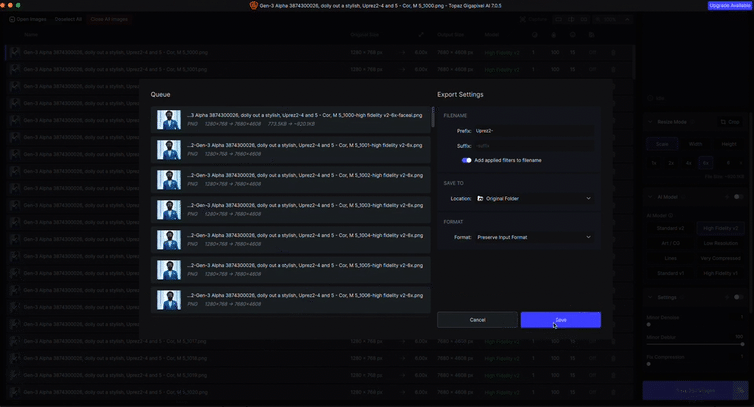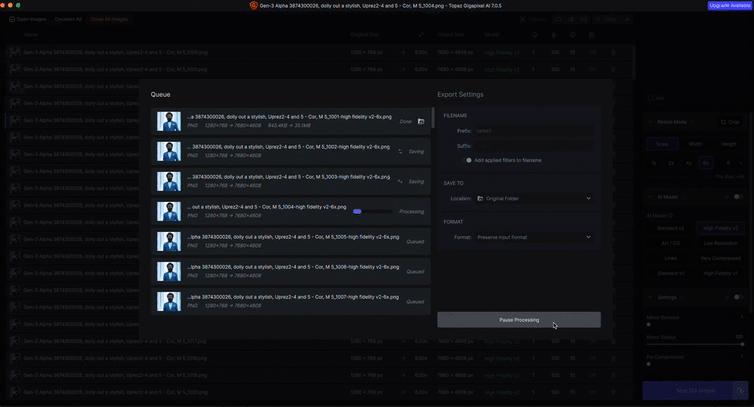
Upscaling
Both Runway and Lumalabs output generative footage at a fairly low resolution compared to today’s film standards. To counter this, we exported all our generated footage as png sequences, and ran them through Topaz Gigapixel AI, which is excellent at filling in the pixel gaps so that we could output everything to a crisp 4K. Gigapixel is designed for stills, and there is a video version – Topaz Video AI – which works with .mp4 and .movs etc., but from our tests for this particular project, we didn’t feel it did as good a job as Gigapixel AI.
Topaz Gigapixel AI
Audio
Eleven Labs is used a great deal at Tilt – whether for generating dummy VOs, producing vocal pickups (if a speaker agrees to us doing so), and even as the final VO in some jobs. For the AI-X project, we first crafted a generative voice that would suit our MidJourney-created character Aeon, by training two off-the-peg Eleven Labs voices into a unique new voice – the first for its accent and empathetic expression, and the second for it’s richer tone. Using this trained voice model, we were then able to create the dialogue track for each of the 50 scripts – combining multiple takes for each to achieve great delivery, and doing this in a carefully planned modular way, so that we didn’t need to keep regenerating lines that were repeated in multiple scripts. A great thing about Eleven Labs is that it offers a certain amount of free regenerations, accepting that like all generative tools, it will not always get things right.
Eleven Labs
Initial Edit
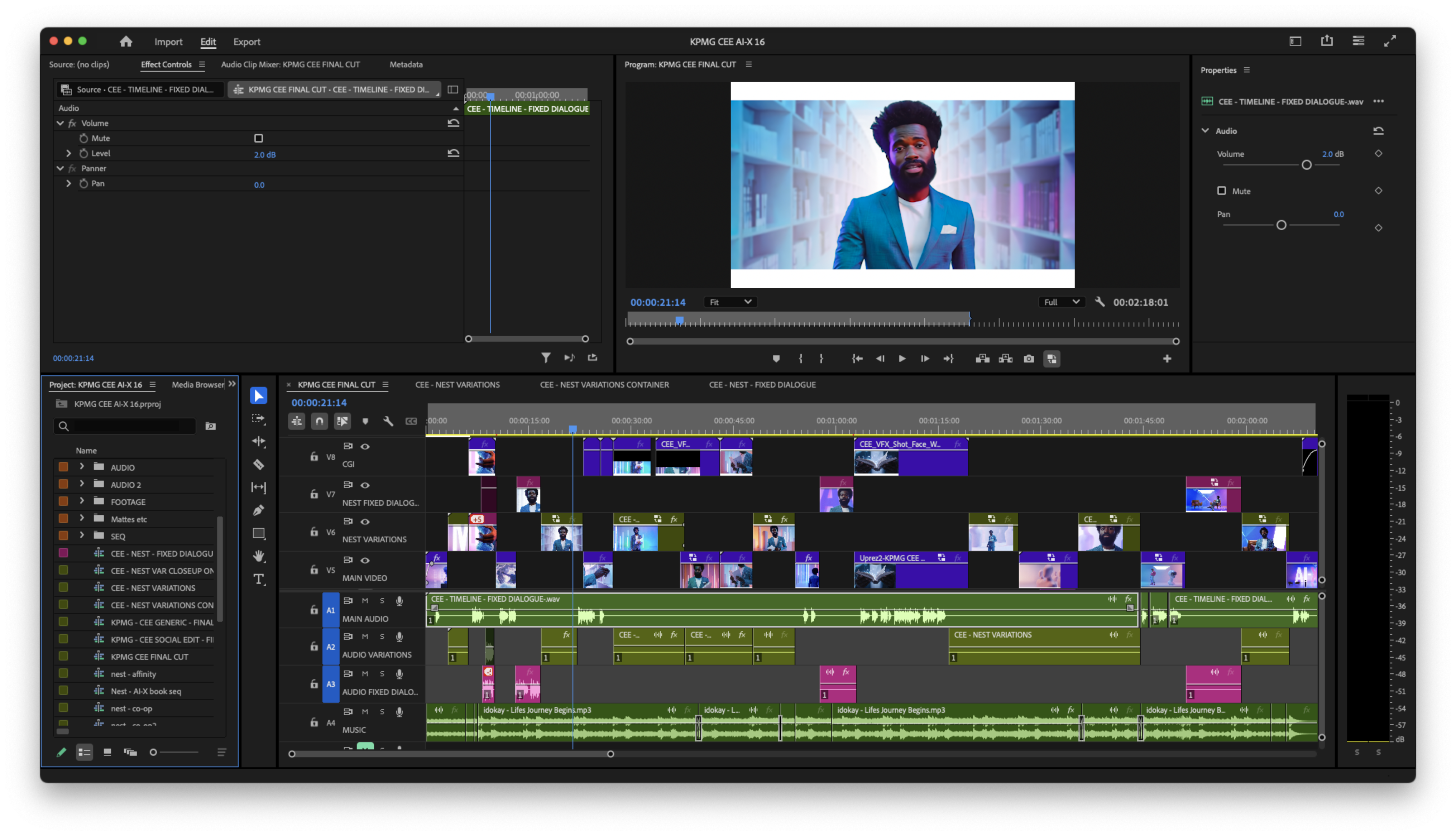
Using the Eleven Labs dialogue and upscaled Runway/Luma footage that we’d generated, we could now shape this all into a 4k edit. There was of course no lip sync as yet, but we layered up the fifty tracks of audio – soloing and tweaking them each individually to make sure they all fitted to the cuts in the footage. We did this in Premiere Pro, using nested sequences for any dialogue that would vary, so that we only needed to export to the lip sync tools, footage that would change. This kept down the cost / time / carbon footprint of the lip sync process, and allowed us to simply drop our received 50 lip synced exports straight into the nested sequence on their own layer – automatically populating the main timeline correctly, and allowing switching between scripts by simply hiding / soloing layers in the nested sequence.
From the nested sequence (not the main edit timeline), the base edit of frames to to be lip synced was exported, along with the 50 individual audio tracks within the nest.
Premiere Pro – nested sequences
Lip sync
The lip sync process required us to combine two different technologies in order to hack together believable dynamic lip synced footage. Most people have seen footage of an AI avatar, where a photo has essentially been made to talk. It was something incredible two or three years ago, but we needed our films to do much more than this. We wanted every camera to be dynamically moving; We wanted our narrator to pass through spaces, gesturing or walking in and out of camera. Like a real film.
LipDub – a high end lip sync tool under BETA access at the time of writing – is excellent at taking an edited traditional film, and lip syncing the mouth movements to multiple languages. Brilliantly, it understands where the cuts are so that you don’t need to lip sync individual shots, instead working on the edit as a whole. It is able to do this amazing task by feeding it training data. You upload as much footage that you have of your characters within each scene / location / lighting setup, so that when it finds that scene in the edit, it has lots of information to go on, when adapting the mouth and face to different words.
The problem we faced was two-fold. Firstly LipDub was not designed to work on generative footage. Would it even work? Thankfully the answer was ‘yes’, once we’d figured out the second challenge: How do we create all the training clips required for LipDub to know what it’s doing? We found the answer in another piece of software, HeyGen.
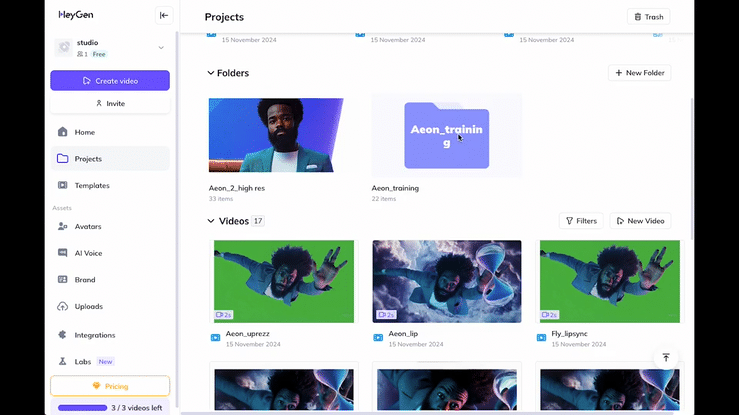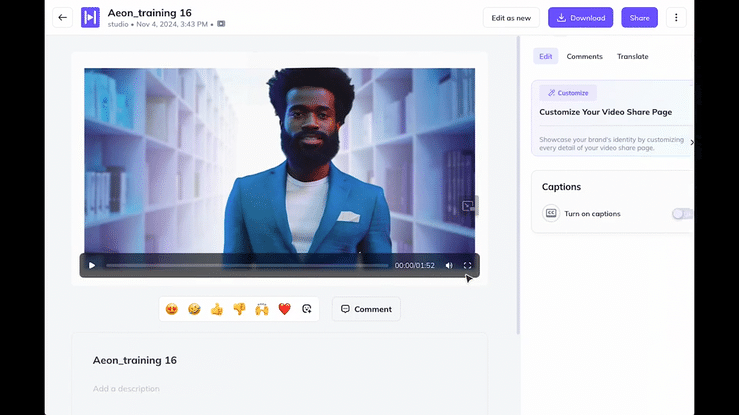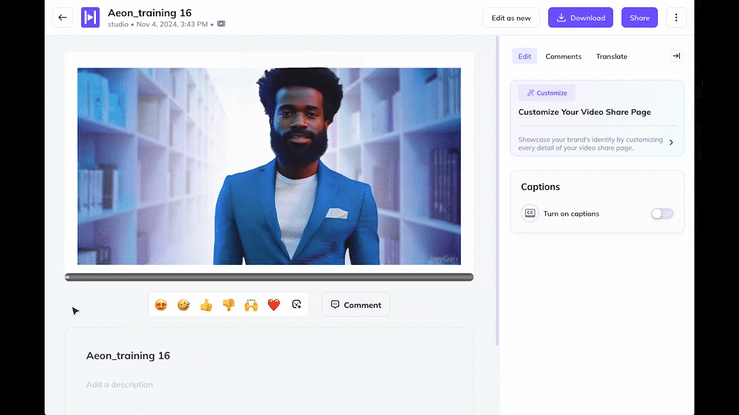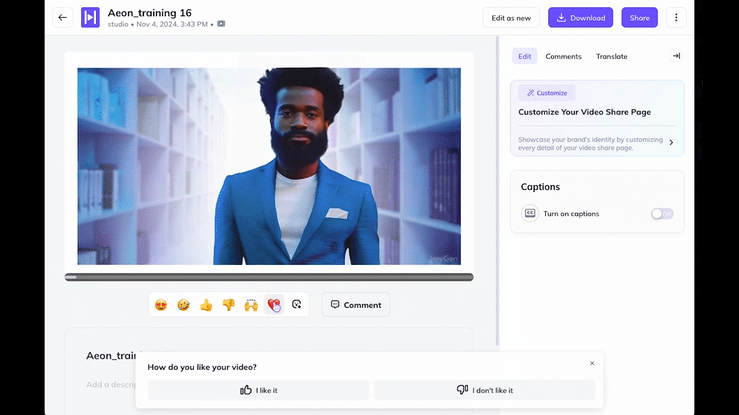
HeyGen is capable to some degree of creating lip sync within dynamically moving shots, but our tests at the time proved it to be far inferior than LipDub at doing so. There would be artifacts around the face where the changing background has not quite rendered correctly, and it had to be input shot-at-a-time as opposed to the entire edit. On the other hand however, HeyGen is particularly good at doing the thing that we didn’t want from this project – creating static camera talking avatars from photographs. So… what if we screen-grabbed stills for every scene in our existing edit, and used HeyGen to get each one speaking a two minute dialogue? Perhaps we could then use these static camera shots as training data for LipDub, and solve the problem. As it turned out we were right, and when we spoke to the engineers at LipDub about what we were doing with their translation tool, they were completely flabbergasted!
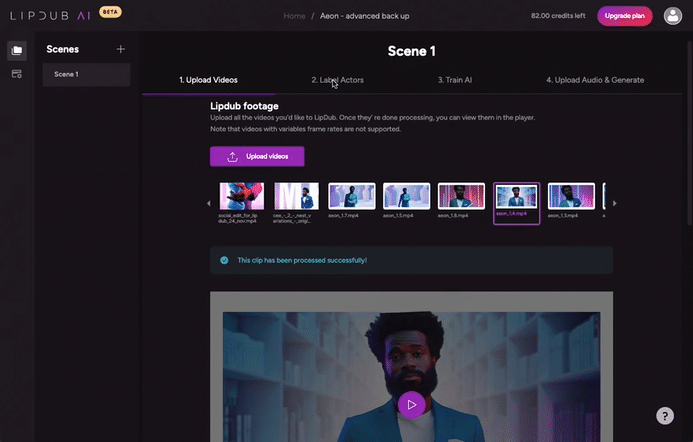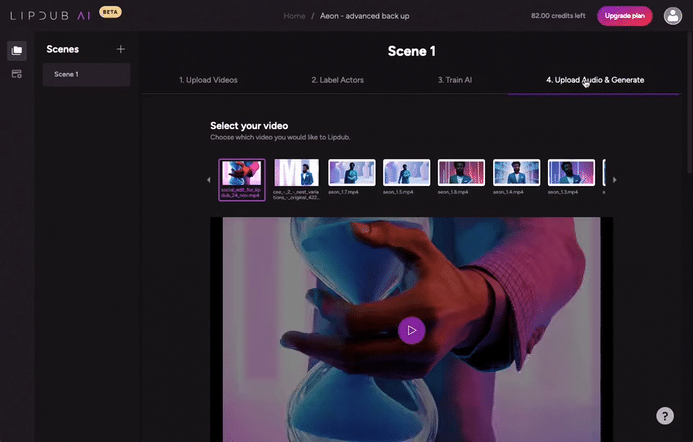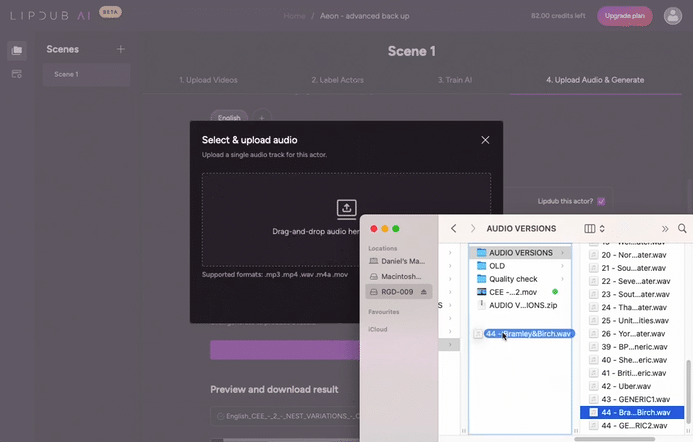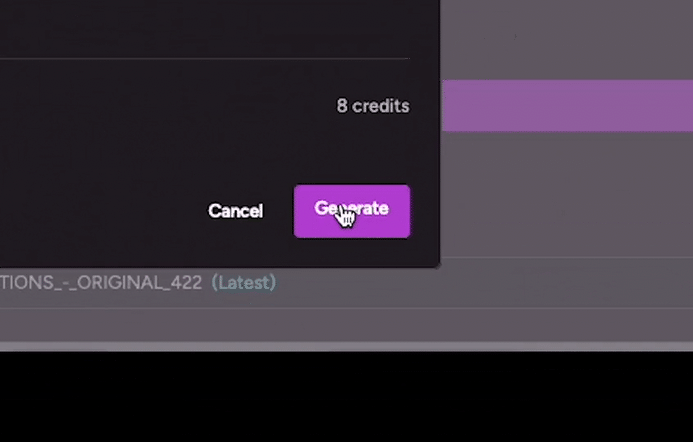
Having uploaded the high res non-lip synced base film from the Premiere nested sequence, the 50 audio exports, and the HeyGen training clips, we were good to go, stacking up 50 exports in LipDub, ready to download and add to layers of our Premiere Pro nested sequence. Lipdub took about 45 minutes per 2 minute film, to do its calculations.
Cgi
The last step before delivery was to patch up any AI wobbliness where necessary in After Effects, and layer in simple cgi such as the writing on the front of the book etc. It’s worth a mention that motion tracking generative footage can prove tricky as it is not spatially correct over time, and some of this had to be done manually frame-by-frame. We’d originally planned to include much more cgi content, however Gen-3 and Dream Machine between them had the majority of this covered.
Delivery
At last, we came to the point of exporting the final films. By using the nested structure of the project, we could simply unhide / unmute each of the 50 video and audio layers in turn within the Premiere nest, and hit export in the main timeline for each of the 50 films – stacking them up in Media Encoder for export.
Conclusions
You may be thinking this all sounds like a very complicated process. You’re right, it was! There were some steep learning curves, big challenges to overcome, late nights, frustrations, and lots of wasted credits. The worst of it was a last-minute heart-stopping few hours where we simply didn’t know how we could deliver anything at all, following a buggy LipDub software update that temporarily kiboshed the entire operation. And perilously close to the hard deadline. This is something to bear in mind with your creative AI stack. When you’re working with BETA software in the cloud, there’s always the possibility that a layer of the stack will fail on you, and bring the whole thing crashing down, leaving you powerless to do anything about it. Try explaining that to even the most empathetic of clients on deadline day!
The challenges aside, when you look at what we have achieved – 50 different almost entirely AI generated cinematic ads, that set a high standard for personalised videos of the future – we can all feel very proud. As technology progresses, I can only imagine that the process will become much simpler, and we’ll be seeing a whole raft of highly personalised film in the future.
Below is the full film – comparing two dialogues to show how the personalisation works:
Thanks for reading. If you’d like to chat about how creative AI can help you, then please get in touch.
SHARE: